Channels
Last updated on 2025-07-05 | Edit this page
Estimated time: 25 minutes
Overview
Questions
- How do I move data around in Nextflow?
- How do I handle different types of input, e.g. files and parameters?
- How can I use pattern matching to select input files?
Objectives
- Understand how Nextflow manages data using channels.
- Create a value and queue channel using channel factory methods.
- Edit channel factory arguments to alter how data is read in.
Channels
Earlier we saw that channels are the way in which Nextflow sends data
around a workflow. Channels connect processes via their inputs and
outputs. Channels can store multiple items, such as values. The number
of items a channel stores, determines how many times a process will run,
using that channel as input.
Note: When the process runs using one item from the input
channel, we will call that run a task. Each task is run in
its own self-enclosed environment.
Why use Channels?
Channels are how Nextflow handles file management, allowing complex tasks to be split up, and run in parallel.
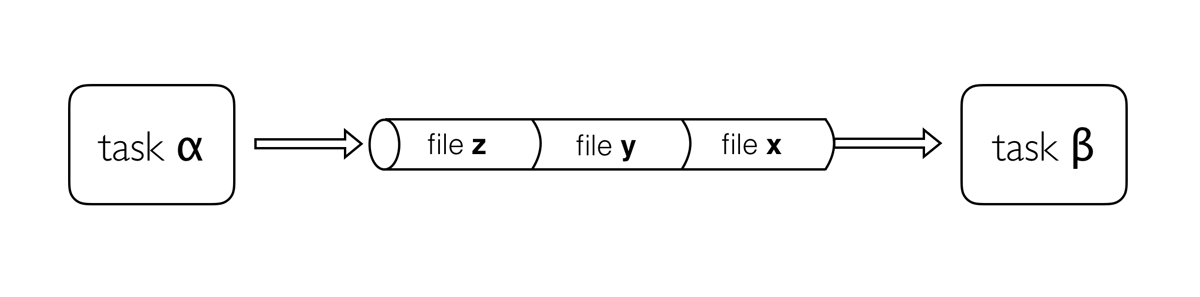
Channels are asynchronous, which means that outputs from a set of processes will not necessarily be produced in the same order as the corresponding inputs went in. However, the first element into a channel queue is the first out of the queue (First in - First out). This allows processes to run as soon as they receive input from a channel. Channels only send data in one direction.
Channel types
Nextflow distinguishes between two different kinds of channels: queue channels and value channels.
Queue channel
Queue channels are a type of channel in which data is consumed (used up) to make input for a process/operator. Queue channels can be created in two ways:
- As the outputs of a process.
- Channel factory methods Channel.of or Channel.fromPath.
Value channels
The second type of Nextflow channel is a value channel.
A value channel is bound to a single
value. A value channel can be used an unlimited number times since its
content is not consumed.
Task 4.1
What type of channel would you use to store the following?
- Multiple values.
- A list with one or more values.
- A single value.
- A queue channels is used to store multiple values.
- A value channel is used to store a single value, this can be a list with multiple values.
- A value channel is used to store a single value.
Navigate to the nextflow file to the 04_channels.nf file (Hint: Ensure your working directory is, training/sgsss-workflow/scripts/). Again this file path will likely look different if you have set up on your local computer.
Creating Channels using Channel factories
Channel factories are used to explicitly create channels. In
programming, factory methods (functions) are a programming design
pattern used to create different types of objects (in this case,
different types of channels). They are implemented for things that
represent more generalised concepts, such as a Channel.
Channel factories are called using the
Channel.<method> syntax, and return a specific
instance of a Channel.
The value Channel factory
The value factory method is used to create a value
channel. Values are put inside parentheses () to assign
them to a channel.
- Creates a value channel and binds a string to it.
- Creates a value channel and binds a list object to it that will be emitted as a single item.
- Creates a value channel and binds a map object to it that will be emitted as a single item.
The value method can only take 1 argument, however, this can be a single list or map containing several elements.
Reminder:
- A List
object can be defined by placing the values in square brackets
[]separated by a comma. - A Map
object is similar, but with
key:value pairsseparated by commas.
To view the contents of a value channel, use the view
operator. We will learn more about channel operators in a later
section.
Queue channel factory
Queue (consumable) channels can be created using the following channel factory methods.
Channel.ofChannel.fromListChannel.fromPathChannel.fromFilePairs
The of Channel factory
When you want to create a channel containing multiple values you can
use the channel factory Channel.of. This allows the
creation of a queue channel with the values specified as
arguments, separated by a ,.
Arguments passed to the of method can be of varying
types e.g., combinations of numbers, strings, or objects. In the above
examples we have examples of both string and number data types.
Channel.from
Task 4.2
Write a Nextflow script that creates a value channel
using meta_verbose_ch as input, containing the list of
values ["all","influence","selection", "none"]. These
represent the different specifications of our models. Essentially we’d
like to conduct a set of model comparison checks by estimating a full
specification and nested sub-models. Open up the nextflow
docs to check the syntax for this.
Then print the contents of the channels using the view
operator. How many lines does the queue and value channel print?
Hint: Use the fromList(), and
value() Channel factory methods. You can also use
of() and try to compare it to fromList(), what
differences do you notice?
Notice we’ve added the following code to 04_channels.nf,
building on the previous workflow definition:
GROOVY
def meta_verbose_ch = ["all","influence","selection", "none"]
workflow {
composition = GENERATE_READS(ZipChannel_dat)
| flatten \
| map { file ->
def key = file.name.toString().split('\\.')[0]
def school_ID = file.name.toString().split("_|\\.")[0]
return tuple(school_ID, key, file)}
composition \
| view
Channel.of(meta_verbose_ch) \
| view
Channel.fromList(meta_verbose_ch) \
| view
}Channel.fromList vs Channel.of
In the above example, the channel has four elements. If you used the
Channel.of(meta_verbose_ch) it would have contained only 1 element
[all, influence, selection, none] and any operator or
process using the channel would run once.
The fromPath Channel factory
The previous channel factory methods dealt with sending general
values in a channel. A special channel factory method
fromPath is used when wanting to pass files.
The fromPath factory method creates a queue
channel containing one or more files matching a file path.
The file path (written as a quoted string) can be the location of a single file or a “glob pattern” that matches multiple files or directories.
The file path can be a relative path (path to the file from the
current directory), or an absolute path (path to the file from the
system root directory - starts with /).
Use the glob syntax to specify pattern-matching behaviour for files. A glob pattern is specified as a string and is matched against directory or file names.
- An asterisk,
*, matches any number of characters (including none). - Two asterisks,
**, works like * but will also search sub directories. This syntax is generally used for matching complete paths. - Braces
{}specify a collection of subpatterns. For example:{period1,period2}matches “period1” or “period2”
For example the script below uses the *.tar.gz pattern
to create a queue channel that contains as many items as there are files
with .tar.gz extension in the data/
folder.
Note The pattern must contain at least a star wildcard character.
You can change the behaviour of Channel.fromPath method
by changing its options. A list of .fromPath options is
shown below.
Available fromPath options:
| Name | Description |
|---|---|
| glob | When true, the characters *, ?,
[] and {} are interpreted as glob wildcards,
otherwise they are treated as literal characters (default: true) |
| type | The type of file paths matched by the string, either
file, dir or any (default:
file) |
| hidden | When true, hidden files are included in the resulting paths (default: false) |
| maxDepth | Maximum number of directory levels to visit (default: no limit) |
| followLinks | When true, symbolic links are followed during directory tree traversal, otherwise they are managed as files (default: true) |
| relative | When true returned paths are relative to the top-most common directory (default: false) |
| checkIfExists | When true throws an exception if the specified path does not exist in the file system (default: false) |
We can change the default options for the fromPath
method to give an error if the file doesn’t exist using the
checkIfExists parameter. In Nextflow, method parameters are
separated by a , and parameter values specified with a
colon :.
If we execute a Nextflow script with the contents below, it will run and not produce an output, or an error message that the file does not exist. This is likely not what we want.
Add the argument checkIfExists with the value
true.
This will give an error as there is no data directory.
Task 4.3
- Navigate to the Nextflow script file called
04_channels.nf. - The pre-populated code involves x5 queue channels. Identify the name of each of these channels. Write comments within your script to explain what this queue channel involves.
- Hint: Run the workflow script through the terminal with
nextflow run. - Hint: use the
.view()operator to print the output of the channel. Again type thenextflow runcommand to run the workflow.
GROOVY
#!/usr/bin/env nextflow
//04_channels.nf
/*
===========================================================
pipeline for independent models runs for each schools
for each time period, implemented in Siena
we can then perform a meta-analysis on the results
@authors
Eleni Omiridou <2333157O@student.gla.ac.uk>
===========================================================
*/
/*
* Default pipeline parameters
*/
params.help = false
params.resume = true
cleanup = true
debug = true
log.info """
====================================================
PARAMETERS
====================================================
batches : ${params.batches}
model specification : ${params.meta}
school data : ${params.school_data}
school info : ${params.school_info}
composition data : ${params.composition_data}
effects : ${params.effects}
subgroup : ${params.subgroup}
"""
if (params.help) {
log.info 'This is the the siena pipeline'
log.info '\n'
exit 1
}
/*
========================================================================================
Workflow parameters are written as params.<parameter>
and can be initialised using the `=` operator.
========================================================================================
*/
Channel
.fromPath(params.meta)
.splitCsv(header: false, sep: '\t')
.set{ pipe_meta }
Channel
.fromPath(params.subgroup)
.splitCsv(header: false, sep: '\t')
.set{ pipe_subgroup }
def map_join(channel_a, key, value){
channel_a
.map{ it -> [it['key'], it['value']] }
}
def flatten_estimation(channel_estimation){
channel_estimation
.map{ it -> [it[0], it[1], it[2], it[3][0], it[3][1], it[3][2], it[3][3], it[4][0], it[4][1], it[4][2], it[4][3], it[5][1]] }
}
// Create a channel for values
Channel
.fromPath(params.effects)
.splitCsv(header: false)
.map { row -> [row[0], row[1], row[2..-1]] }
.set{ pipe_effects }
Channel
.fromPath(params.school_info)
.splitJson()
.set{ pipe_school_info }
/*
========================================================================================
Input data is received through channels
========================================================================================
*/
//import modules
def ZipChannel_dat = Channel.fromPath(params.composition_data) // change this to composition_sub whenever data file name changes
/*
========================================================================================
Main Workflow
========================================================================================
*/
workflow {
composition = GENERATE_READS(ZipChannel_dat)
| flatten \
| map { file ->
def key = file.name.toString().split('\\.')[0]
def school_ID = file.name.toString().split("_|\\.")[0]
return tuple(school_ID, key, file)}
pipe_meta.view()
// pipe_school_info.view()
// pipe_effects.view()
// pipe_subgroup.view()
// composition.view()
}
/*
========================================================================================
A Nextflow process block. Process names are written, by convention, in uppercase.
This convention is used to enhance workflow readability.
========================================================================================
*/
process GENERATE_READS{
input:
path targz
publishDir "$projectDir/tmp", mode: "copy", overwrite: true
output:
path "*"
script:
"""
tar -xzf $targz
# Print file name
printf '${targz}\\t'
"""
}Run the code using the following command on the terminal:
The fromFilePairs Channel factory
We have seen how to process files individually using
fromPath.
Another alternative is to use fromFilePairs to return a
grouping of data, represented as a list in the groovy syntax.
- The first element of the tuple emitted is a string based on the
shared part of the filenames (i.e., the
*part of the glob pattern). - The second element is the list of files matching the remaining part
of the glob pattern (i.e., the
*each_period.tar.gzpattern). This will include any sets of data that involve compressed folders.
What if you want to capture more than a pair?
If you want to capture more than two files for a pattern you will
need to change the default size argument (the default value
is 2) to the number of expected matching files.
The code above will create a queue channel containing one element.
See more information about the channel factory
fromFilePairs here
Task 4.4
Use the fromFilePairs method to create a channel
containing four tuples. Each tuple will contain the pairs of data reads
for the four schools with synthetic data in the tmp/
directory. Make sure you have previously completed Task 3.3, or check
your tmp/ folder contains both data files,
.RDS, as well as auxiliary data files,
.dat.
OUTPUT
[school123_period2, [/workspaces/training/sgsss-workflow/scripts/tmp/school123_period2.RDS, /workspaces/training/sgsss-workflow/scripts/tmp/school123_period2.dat]]
[school124_period2, [/workspaces/training/sgsss-workflow/scripts/tmp/school124_period2.RDS, /workspaces/training/sgsss-workflow/scripts/tmp/school124_period2.dat]]
[school126_period1, [/workspaces/training/sgsss-workflow/scripts/tmp/school126_period1.RDS, /workspaces/training/sgsss-workflow/scripts/tmp/school126_period1.dat]]
[school124_period1, [/workspaces/training/sgsss-workflow/scripts/tmp/school124_period1.RDS, /workspaces/training/sgsss-workflow/scripts/tmp/school124_period1.dat]]
[school125_period1, [/workspaces/training/sgsss-workflow/scripts/tmp/school125_period1.RDS, /workspaces/training/sgsss-workflow/scripts/tmp/school125_period1.dat]]
[school123_period1, [/workspaces/training/sgsss-workflow/scripts/tmp/school123_period1.RDS, /workspaces/training/sgsss-workflow/scripts/tmp/school123_period1.dat]]
[school126_period2, [/workspaces/training/sgsss-workflow/scripts/tmp/school126_period2.RDS, /workspaces/training/sgsss-workflow/scripts/tmp/school126_period2.dat]]
[school125_period2, [/workspaces/training/sgsss-workflow/scripts/tmp/school125_period2.RDS, /workspaces/training/sgsss-workflow/scripts/tmp/school125_period2.dat]]
- Channels must be used to import data into Nextflow.
- Nextflow has two different kinds of channels: queue channels and value channels.
- Data in value channels can be used multiple times in workflow.
- Data in queue channels are consumed when they are used by a process or an operator.
- Channel factory methods, such as
Channel.of, are used to create channels. - Channel factory methods have optional parameters e.g.,
checkIfExists, that can be used to alter the creation and behaviour of a channel.