Introduction
Last updated on 2025-06-28 | Edit this page
Overview
Questions
- What are the FAIR research principles?
- How do FAIR principles apply to software?
- How does folder organisation help me?
Objectives
- Explain the FAIR research principles in the context of research software
- Explain how file management helps in being FAIR
- Understand elements of good naming strategy
FAIR principles
FAIR stands for Findable, Accessible, Interoperable, and Reusable and comprises a set of principles designed to increase the visibility and usefulness of your research to others. FAIR principles have been applied for software, here is a brief concept translation:
Findable
- Create a description of your software to make it discoverable by search engines and other search tools
- Use a unique and persistent identifier (DOI) for your software (e.g. by depositing your code on Zenodo, OSF, GitHub)
Accessible
- The code and its description (metadata) has to be available even when the software is no longer actively developed (this includes earlier versions of the software)
Interoperable
- Use community-agreed standard formats for inputs and outputs of your software and its metadata
Reusable
- Document your software (including its functionality, how to install and run it) so it is both usable (can be executed) and reusable (can be understood, modified, built upon, or incorporated into other software)
- Give a licence to your software clearly stating how it can be reused
Task 1.1

The Turing Way project illustration by Scriberia. Used under a CC-BY 4.0 licence. DOI: 10.5281/zenodo.3332807.
Join Menti: https://www.menti.com/alg8a76zkfgp
File Naming
There is no single way to manage file naming, but consistency is key. Here’s a couple of options, and ways you can combine approaches:
| Case Convention | Example |
|---|---|
| Pascal Case | PascalCase |
| Camel Case | camelCase |
| Snake Case | snake_case |
| Kebab Case | kebab-case |
| Flat Case | flatcase |
| Upper Flat Case | UPPERFLATCASE |
| Pascal Snake Case | Pascal_Snake_Case |
| Camel Snake Case | camel_Snake_Case |
| Screaming Snake Case | SCREAMING_SNAKE_CASE |
It’s good practice to mention your file naming convention in your data management plan and/or meta data.
- Choose a convention and apply it consistently
- Use descriptive names
- Optional: Tap into default ordering
- Optional: Build file naming in your workflow
Task 1.2
Before we dive into the details, let’s look at some examples of file names, and come up with suggestions to improve clarity and functionality.
| 🔨 Needs work | ✔️ Suggestion |
|---|---|
School123 Period1.RDS |
|
period1_school123_A_ITER2_CONVERGED_SIM.RDS |
|
school123_period1_I_goodness_fit.png |
| 🔨 Needs Edits | ✔️ Suggestion |
|---|---|
School123 Period1.RDS |
school123_period1.RDS |
period1_school123_A_ITER2_CONVERGED_SIM.RDS |
school123_period1_A_ITER2_CONVERGED_SIM.RDS |
school123_period1_I_goodness_fit.png |
school123_period1_I_gof.png |
Default ordering
To create a default ordering, we can add a number or date at the
beginning of file names. This keeps our files sorted in ascending order
based on file versions or in chronological order. If your file name
starts with a number, we recommend left padding them with zeros, because
your computer will order 003 < 004 < 020 < 100 as
opposed to 100 < 20 < 3 < 4. If you need to
re-order your files at a later point, you may be tempted to re-name all
of your files. It is best to use a template from the start to avoid
running into this mess.
There are certain conventions that apply to file naming, ex. if you
need to use a date then file names can start with
year-month-day (for example 2020-02-21). We
recommend using something like the ISO 8601 standard:
YYYY-MM-DD for dates.
Dynamically generated
Output in multiple forms can be generated as part of running a
computational pipeline. Result files can contain a key identifier or
label, depending on your unit of analysis. Workflow managers offer
important scaffolding to support how you track the
flows of inputs and outputs across multiple stages of a
pipeline. The identifier may well be a pseudonym if your project works
with confidential data. We can come back to this to see how we can
assign handy process labels in our workflow with base functions
like paste0() in R statistical software. This way
we can concatenate literal words or values with ones that depend on the
input flowing into a process.
Adapting a Workflow
A repository (or a “repo”) is a storage location for your research project. A repository can contain a range of digital objects and can be used to store your project by using online platforms such as GitHub. The aim of a repository is to organise your project in such a way that is both accessible to others and efficient to use.
So far, we saw the key documents that one should add when starting or setting up a project repository. If you are following along, navigate to repo-boilerplate.
Example for a Research Project
A good way to map the organisation of folders within your directory is using a file tree.
Task 1.3
Here are some suggestions on the files and folders your workflow should have, you can download the template for the folder here:
Project folder
└── 📁workflow <- Main workflow directory
└── 📁apptainer <- Container definitions for Apptainer (formerly Singularity)
└── 📁bin <- Executable scripts used in the workflow, ex. in R these would be functions
└── 📁conf <- Configuration files for different execution environments
└── 📁data <- Input data files for the workflow
└── 📁docker <- Docker container definition and dependencies
└── 📁docs <- Documentation, reports, and visualizations
└── 📁modules <- Nextflow modules for different analysis steps
└── 📁params <- Parameter files for the workflow
└── 📁templates <- Template scripts used in the workflow
└── .dockerignore <- Files to exclude from Docker builds
└── .gitignore <- Files to exclude from Git version control
└── main.nf <- Main Nextflow workflow definition
└── nextflow.config <- Main Nextflow configuration
└── params.config <- Parameter configuration
└── README.md <- Project documentationStep 1: Follow the link to repo-boilerplate to navigate to the code repository.
Step 2: Click on the code tab to download the folders for the workflow.
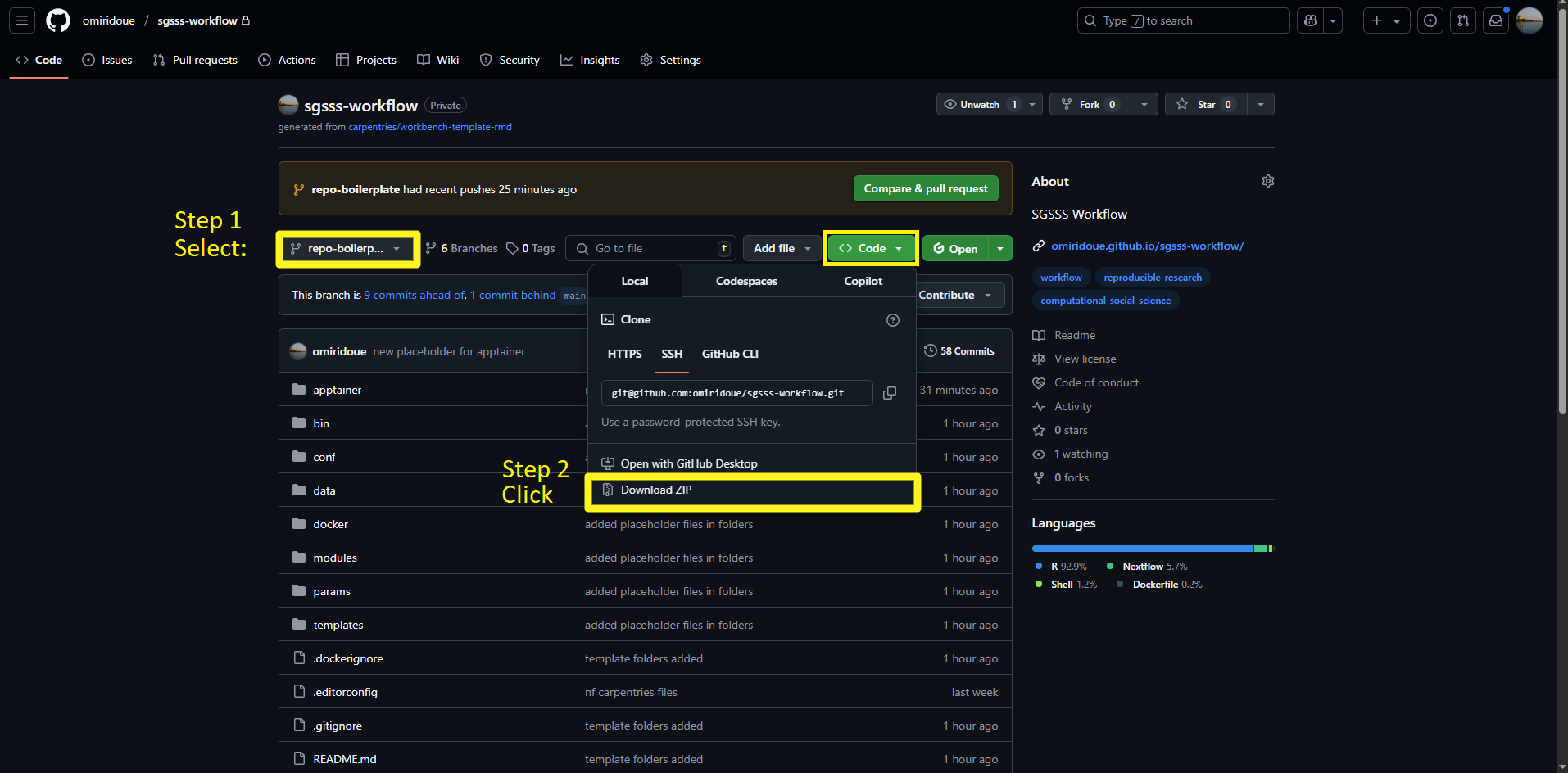
Alternatively, you can use git to download the code for the specific branch, with the following code:
Example repositories
- Name your files consistently
- Keep it short but descriptive
- Share/establish a naming convention when working with collaborators
- Consider generating output file names dynamically
- Avoid special characters or spaces to keep it machine-compatible
- Use capitals or underscores to keep it human-readable
- Use consistent date formatting, for example ISO 8601:
YYYY-MM-DDto maintain default order - Include a version number when applicable
- Record a naming convention in your data management plan